07-spark-stage-源码分析
stage 划分过程
基本概念说明
- 没有父stage的stage 可以直接提交进行计算,因为没有依赖
- 有父stage的stage,不可以直接提交进行计算,因为有依赖,必须等父stage处理完成后,才可以进行计算
- org.apache.spark.scheduler.DAGScheduler-->handleMapStageSubmitted 中调用submitStage(finalStage),把最终的stage作为参数传递,注意handleMapStageSubmitted函数中,除了有 submitStage(finalStage)调用,还有submitWaitingStages()调用
- submitStage(finalStage) 提交没有父stage 的stage,并把有父stage的stage递归加入到集合 waitingStages中
- submitWaitingStages 循环提交集合中的stage,此时,集合中的所有的stage是有依赖关系的,并且他们的执行是有顺序的,因为后面的stage依赖前边的stage的计算
stage 图解
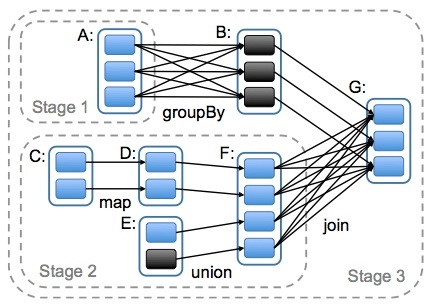
stage 提交源码分析
submiStage 源码分析
/** Submits stage, but first recursively submits any missing parents. * 提交stage, 但是先递归提交,漏掉的stage(即依次递归父stage,从最顶层stage开始提交) */ private def submitStage(stage: Stage) { val jobId = activeJobForStage(stage) if (jobId.isDefined) { logDebug("submitStage(" + stage + ")") if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) { //得到stage的直接父stages(可能是一个或多个) val missing = getMissingParentStages(stage).sortBy(_.id) logDebug("missing: " + missing) if (missing.isEmpty) { logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents") //提交stage中的TaskSet submitMissingTasks(stage, jobId.get) } else { for (parent <- missing) { submitStage(parent) } /** *因为有父stage,不能直接计算,所以都放到等待计算的stages中,此时不管先后顺序,因为计算的时候会先按stage的firstJobId排序 */ waitingStages += stage } } } else { abortStage(stage, "No active job for stage " + stage.id, None) } }- submitWaitingStages 源码分析
/** * Check for waiting or failed stages which are now eligible for resubmission. * Ordinarily run on every iteration of the event loop. * 检查 待待的或失败的 stages 现在是适合重新提交 * 通常对事件循环的每次迭代运行。 */ private def submitWaitingStages() { // TODO: We might want to run this less often, when we are sure that something has become // runnable that wasn't before. logTrace("Checking for newly runnable parent stages") logTrace("running: " + runningStages) logTrace("waiting: " + waitingStages) logTrace("failed: " + failedStages) val waitingStagesCopy = waitingStages.toArray waitingStages.clear() for (stage <- waitingStagesCopy.sortBy(_.firstJobId)) { submitStage(stage) } }
stage 划分
- 1, Spark Application中可以因为不同的Action触发众多的Job,也就是说一个Application中可以有很多的Job,每个Job是由一个或者多个Stage构成的,后面的Stage依赖于前面的Stage,也就是说只有前面依赖的Stage计算完毕后,后面的Stage才会运行;
- 2, Stage划分有宽依赖,也有窄依赖,什么产生宽依赖呢?例如reducByKey、groupByKey等等,可以产生宽依赖;;
3, 由Action(例如collect)导致了SparkContext.runJob的执行,最终导致了DAGScheduler中的submitJob的执行,其核心是通过发送一个case class JobSubmitted对象给eventProcessLoop
AppClient --> registerWithMaster -->
master 注册 application 持久化 application 发送给driver,报告注册状态 为应用程序可用资源调度(分配资源)
--> DAGScheduler
--> textFile.count()
-->sc.runJob
-->submitJob
-->dagScheduler.runJob
-->eventProcessLoop.post(JobSubmitted( jobId, rdd, func2, partitions.toArray, callSite, waiter, SerializationUtils.clone(properties)))
-->/** *消息循环就是线程不断循环消息队列,所以可以不断的发消息,例如不断的提交新的Job,这样就可以不断的处理了 *那个线程没有消息的时候是阻塞的,来消息的时候才处理 * An event loop to receive events from the caller and process all events in the event thread. It * will start an exclusive event thread to process all events. * * Note: The event queue will grow indefinitely. So subclasses should make sure `onReceive` can * handle events in time to avoid the potential OOM. */ private[spark] abstract class EventLoop[E](name: String) extends Logging { private val eventQueue: BlockingQueue[E] = new LinkedBlockingDeque[E]() private val stopped = new AtomicBoolean(false) private val eventThread = new Thread(name) { setDaemon(true) override def run(): Unit = { try { while (!stopped.get) { val event = eventQueue.take() try { onReceive(event) } catch { case NonFatal(e) => { try { onError(e) } catch { case NonFatal(e) => logError("Unexpected error in " + name, e) } } } } } catch { case ie: InterruptedException => // exit even if eventQueue is not empty case NonFatal(e) => logError("Unexpected error in " + name, e) } } } def start(): Unit = { if (stopped.get) { throw new IllegalStateException(name + " has already been stopped") } // Call onStart before starting the event thread to make sure it happens before onReceive onStart() eventThread.start() }
-->回调 DAGScheduler onReceive 方法
-->case JobSubmitted
-->def handleJobSubmitted
--> newResultStage stage 包含了 父 stage
--> submitStage
-->submitMissingTasks
任务本地性算法的实现
val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try {
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
val job = s.activeJob.get
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
}
} catch {
case NonFatal(e) =>
stage.makeNewStageAttempt(partitionsToCompute.size)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
abortStage(stage, s"Task creation failed: $e\n${e.getStackTraceString}", Some(e))
runningStages -= stage
return
}
-->getPreferredLocs
org.apache.spark.scheduler.DAGSchedulerEventProcessLoop
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match { case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) => dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)-> private[scheduler] def handleJobSubmitted -> private def submitStage(stage: Stage)
/**
* Submits stage, but first recursively submits any missing parents.
* 提交stage,先递归提交所有的父级stage(漏掉的父级stage)
*/
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
//提交漏掉的tasks
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
-->
org.apache.spark.scheduler.DAGScheduler --> private def submitMissingTasks
-->
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())