spark-1.6.0-bin-hadoop2.6-安装
准备工作
安装好hadoop集群
安装好scala
scala-2.10.6 版本spark安装包
spark-1.6.0-bin-hadoop2.6.tgzubuntu操做系统15桌面版
集群环境如下
s0为master主控制节
192.168.0.110 s0 192.168.0.111 s1 192.168.0.112 s2 192.168.0.113 s3 192.168.0.114 s4集群配置说明
先在s0上配置完成所有配置信息,然后同步到所有集群每一个节点上,所有配置包括安装路径是一样的
操作步骤
解压安装包
tar -zxvf spark-1.6.0-bin-hadoop2.6.tgz -C /opt/modules/bigdata/spark 即:$SPARK_HOME=/opt/modules/bigdata/spark/spark-1.6.0-bin-hadoop2.6
修改配置文件
$SPARK_HOME/conf/spark-env.sh
复制$SPARK_HOME/conf/spark-env.sh.template 为 $SPARK_HOME/conf/spark-env.sh 修改$SPARK_HOME/conf/spark-env.sh 增加 export JAVA_HOME=/opt/modules/environment/jdk/jdk1.8.0_65 export SCALA_HOME=/opt/modules/environment/scala/scala-2.10.6 export HADOOP_HOME=/opt/modules/bigdata/hadoop/hadoop-2.6.0 export HADOOP_CONF_DIR=/opt/modules/bigdata/hadoop/hadoop-2.6.0/etc/hadoop export SPARK_MASTER_IP=s0 export SPARK_WORKER_MEMORY=1500M export SPARK_EXECUTOR_MEMORY=1500m export SPARK_DRIVER_MEMORY=1500m export SPARK_WORKER_CORES=2cp $SPARK_HOME/conf/slaves.template $SPARK_HOME/conf/slaves 在末尾增加
s0 s1 s2 s3cp $SPARK_HOME/conf/spark-defaults.conf.template $SPARK_HOME/conf/spark-defaults.conf
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three" spark.eventLog.enabled true spark.eventLog.dir hdfs://s0:9000/historyserverforSpark spark.yarn.historyServer.address s0:18080 spark.history.fs.logDirectory hdfs://s0:9000/historyserverforSpark #spark.default.parallelism 100
- 启动spark
$SPARK_HOME/sbin/start-all.sh 关闭spark
$SPARK_HOME/sbin/stop-all.sh启动历史记录服务
$SPARK_HOME/sbin/start-history-server.sh关闭历史记录服务
$SPARK_HOME/sbin/stop-history-server.sh访问界面
访问 http://S20:8080 访问 http://S20:18080
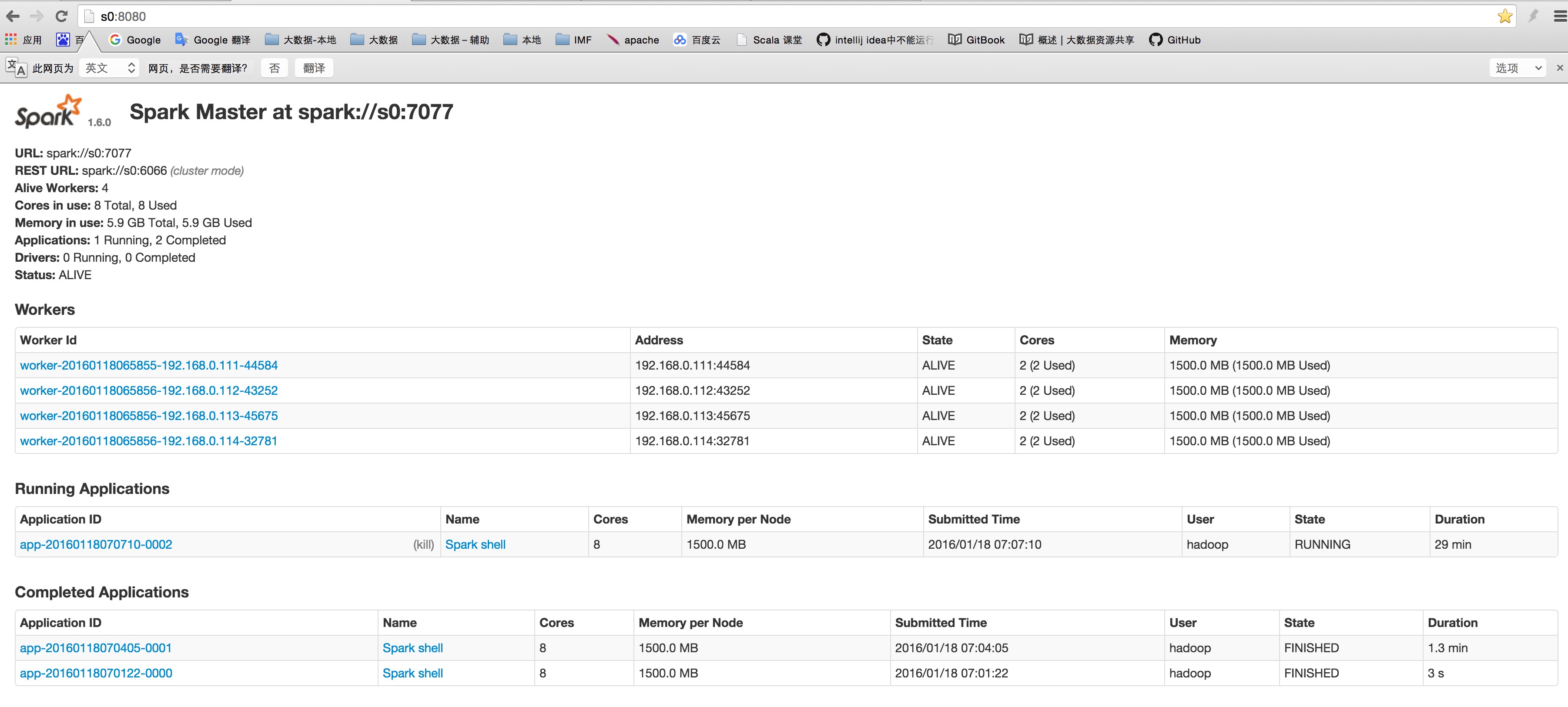](spark_master.png)
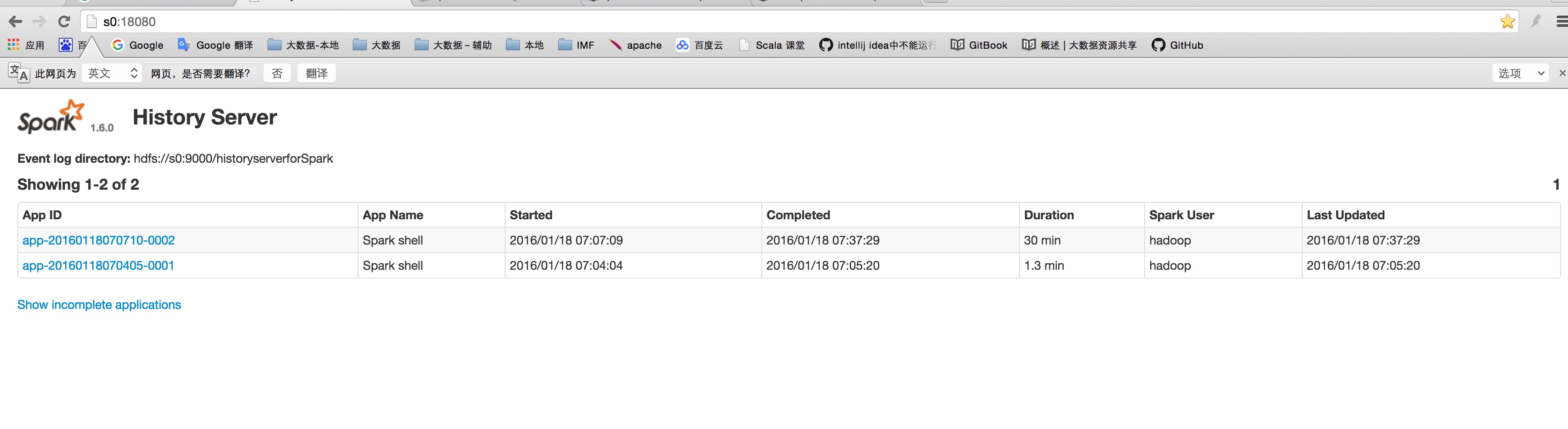
提交并行计算
$SPARK_HOME/bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://s0:7077 ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 1000连接客户端工具 Shell
$SPARK_HOME/bin/spark-shell --master spark://s0:7077统计单词数量
sc.textFile("/library/wordcount/input/Data").flatMap(_.split(" ")).map(word => (word,1)).reduceByKey(_+_).map(pair => (pair._2,pair._1)).sortByKey(false).map(pair => (pair._2,pair._1)).saveAsTextFile("/library/wordcount/output/spark_word_count")