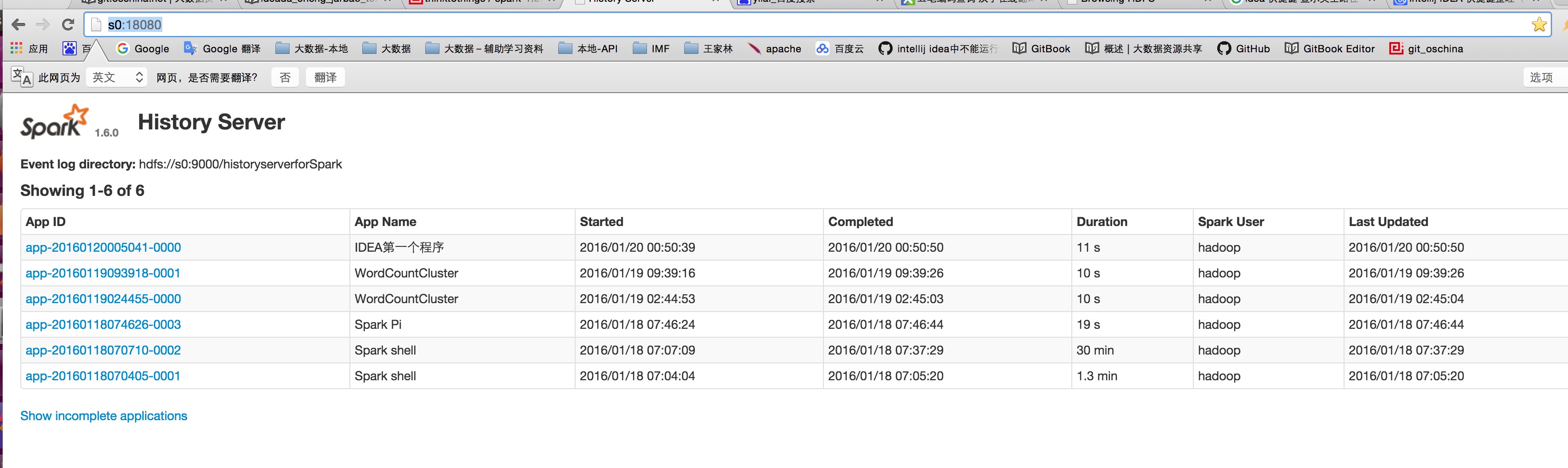
idea打成jar包通过spark-submit工具部署
准备工作
新建好scala 项目,并集成spark-hadoop依赖
新建scala项目,并引用spark-hadoop集成包(scala-sdk-2.10.6,spark-assembly-1.6.0-hadoop2.6.0.jar)
操作步骤
新建scala项目
打开idea开发工具==>File==>New==>Project==>Scala==>Scala ==>Next==>
Project name:填写自己的项目名称 Project location:填写自己的项目在本地磁盘存放的路径 Project SDK:点击New找到jdk安装根路径(1.8以上),选中根目录 Scala SDK: 点击Create找到scala安装根路径(scala-2.10.6)
==>Finish添加spark-hadoop集成包 选中项目 ==>右键==>Open Module Setting==>Global Libraries==> 点+按钮选Java,找到spark-assembly-1.6.0-hadoop2.6.0.jar==>OK==>OK
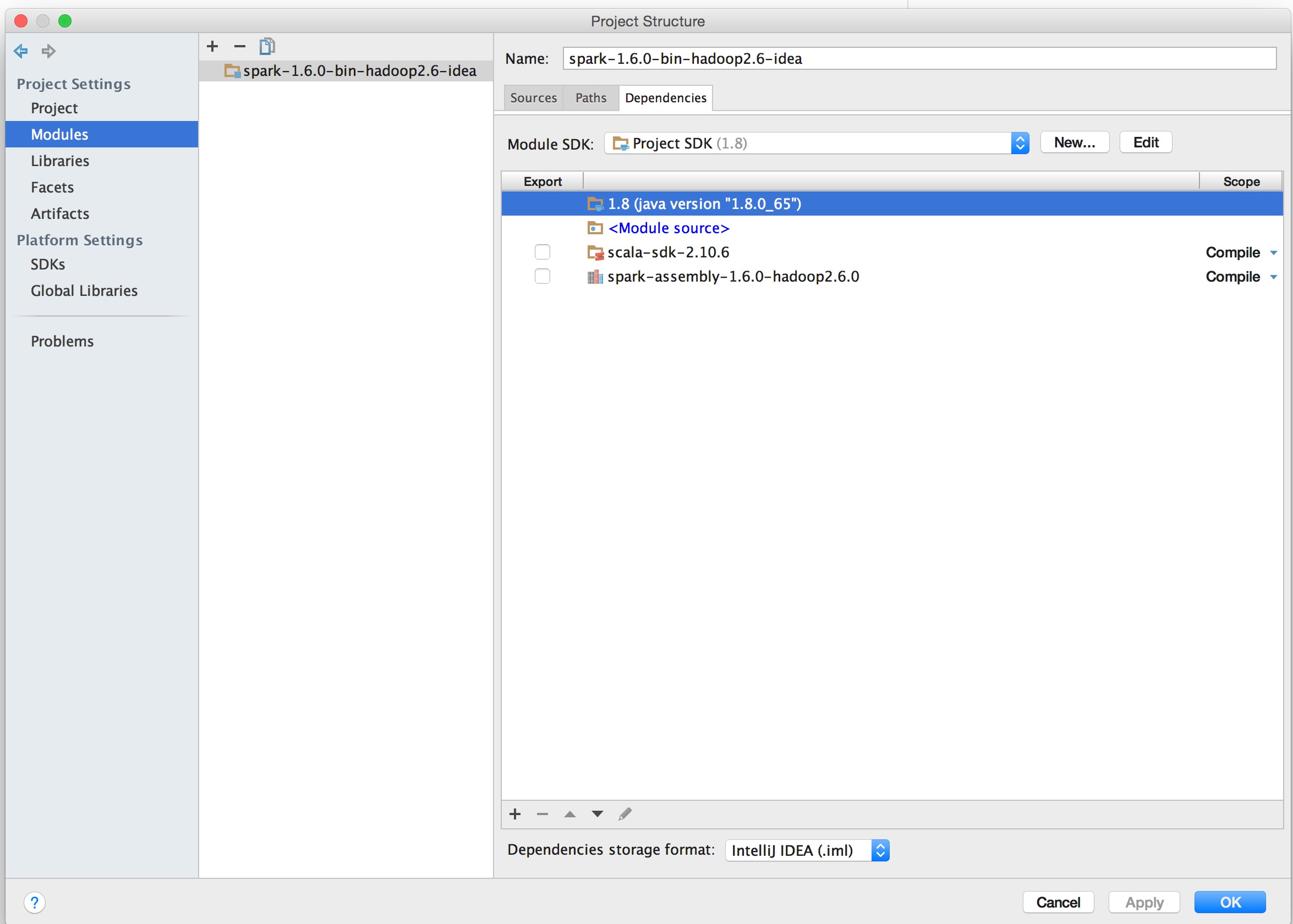
项目的依赖关系如图
新建WordCount.scala
package com.opensourceteam.model.common.bigdata.spark.quickstart
import org.apache.spark.{SparkConf,SparkContext}
/**
* 开发者:刘文 Email:372065525@qq.com
* 16-1-19 下午11:07
* 功能描述:
*/
object WordCount extends App{
/**
* 第一步:创建Spark的配置对象SparkConf,设置Spark程序的运行时的配置信息,例如说通过setMaster来设置程序
* 要连接的Spark集群的Master的URL,如果设置为local,则代表Spark程序在本地运行,特别适合机器配置条件非常差
*/
val conf = new SparkConf
/**
* appname: 应用的名称
* master:主机地址
* 本地,不运行在集群值:local
* 运行在集群:spark://s0:7077
*/
conf.setAppName("IDEA第一个程序").setMaster("spark://s0:7077")
/**
* 创建SparkContext对象
* SparkContext 是Spark程序的所有功能的唯一入口,无论是采用Scal,Java,Python,R等
* 同时还会负则Spark程序往Master注册程序等
* SparkContext是整个Spark应用程序中最为至关重要的一个对象
*/
val sc =new SparkContext(conf)
/**
* 根据具体的数据来源(HDFS、Hbse、local Fs、DB、S3等通过SparkContext来创建RDD)
* RDD创建有三种方式:根据外部的数据来源例 如HDFS、根据Scala集合、由其它的RDD操作
* 数据会被RDD划分成为一系列的Patitions,分配到每个Patition的数据属于一个Task的处理范畴
*/
val path = "/library/wordcount/input/Data"
val lines = sc.textFile(path, 3) //读取文 件,并设置为一个Patitions (相当于几个Task去执行)
val mapArray = lines.flatMap { x => x.split(" ") } //对每一行的字符串进行单词拆分并把把有行的拆分结果通过flat合并成为一个结果
val mapMap = mapArray.map { x => (x,1) }
val result = mapMap.reduceByKey(_+_) //对相同的Key进行累加
result.collect().foreach(x => println("key:"+ x._1 + " value" + x._2))
val resultValue = result.map(x =>(x._2,x._1))
val resultOrder = resultValue.sortByKey(false).map(x => (x._2 ,x._1))
resultOrder.collect().foreach(x => println("key:"+ x._1 + " value:" + x._2))
// result.saveAsTextFile("output")
sc.stop()
}
- 将项目打成jar 包
选中项目==>右键==>Open Module Settings==>Artifacts==>点+按钮选JAR==>From Modules With Dependencies...
Module:选当前项目
Main Class:选中默认的入口程序,可不填,但此时运行Jar文件时需要指定入口类的全路径
Jar files from libraries ==> 选择 extract to the target JAR ==>OK
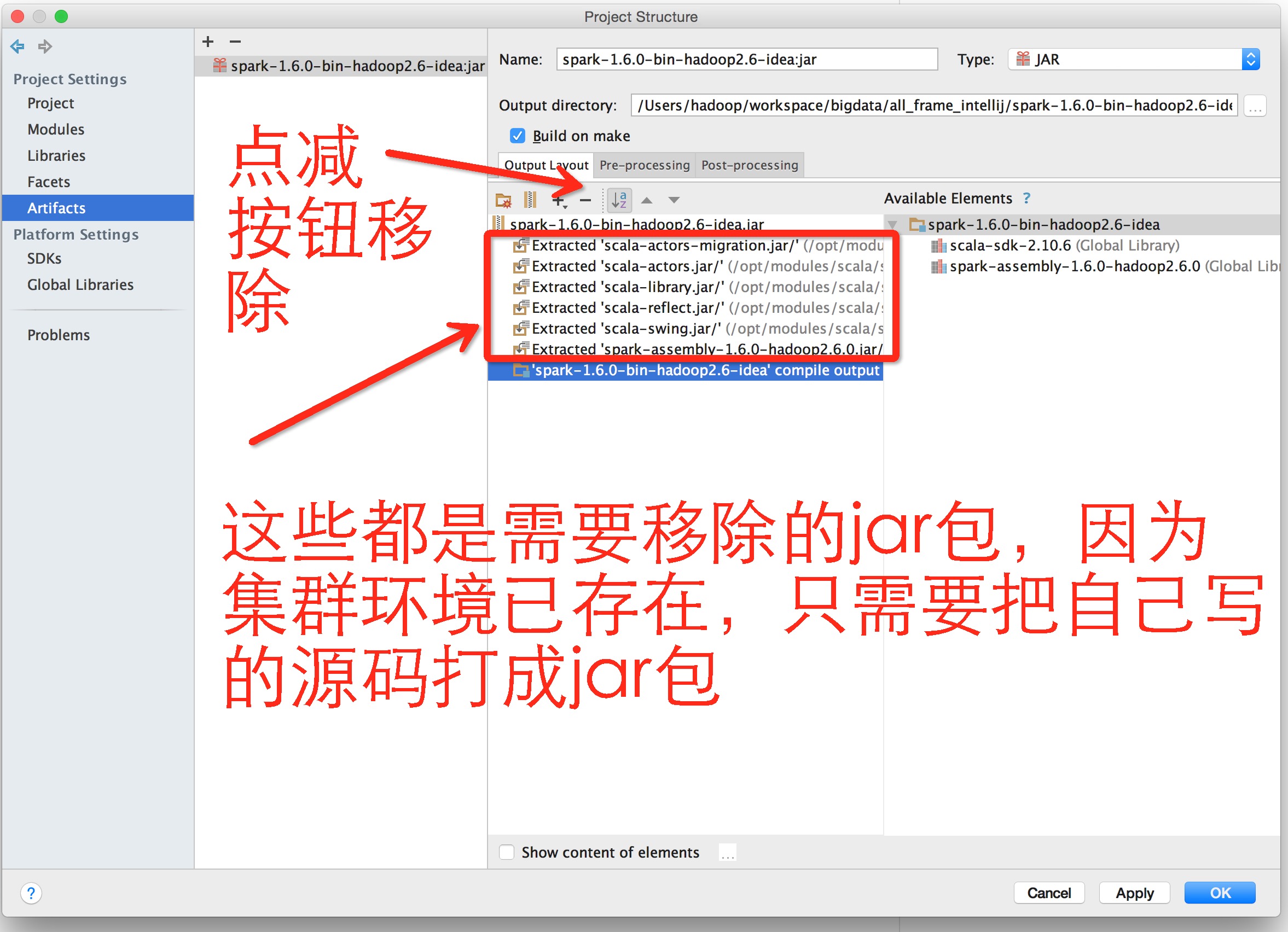 结果如图
最后点OK
结果如图
最后点OK
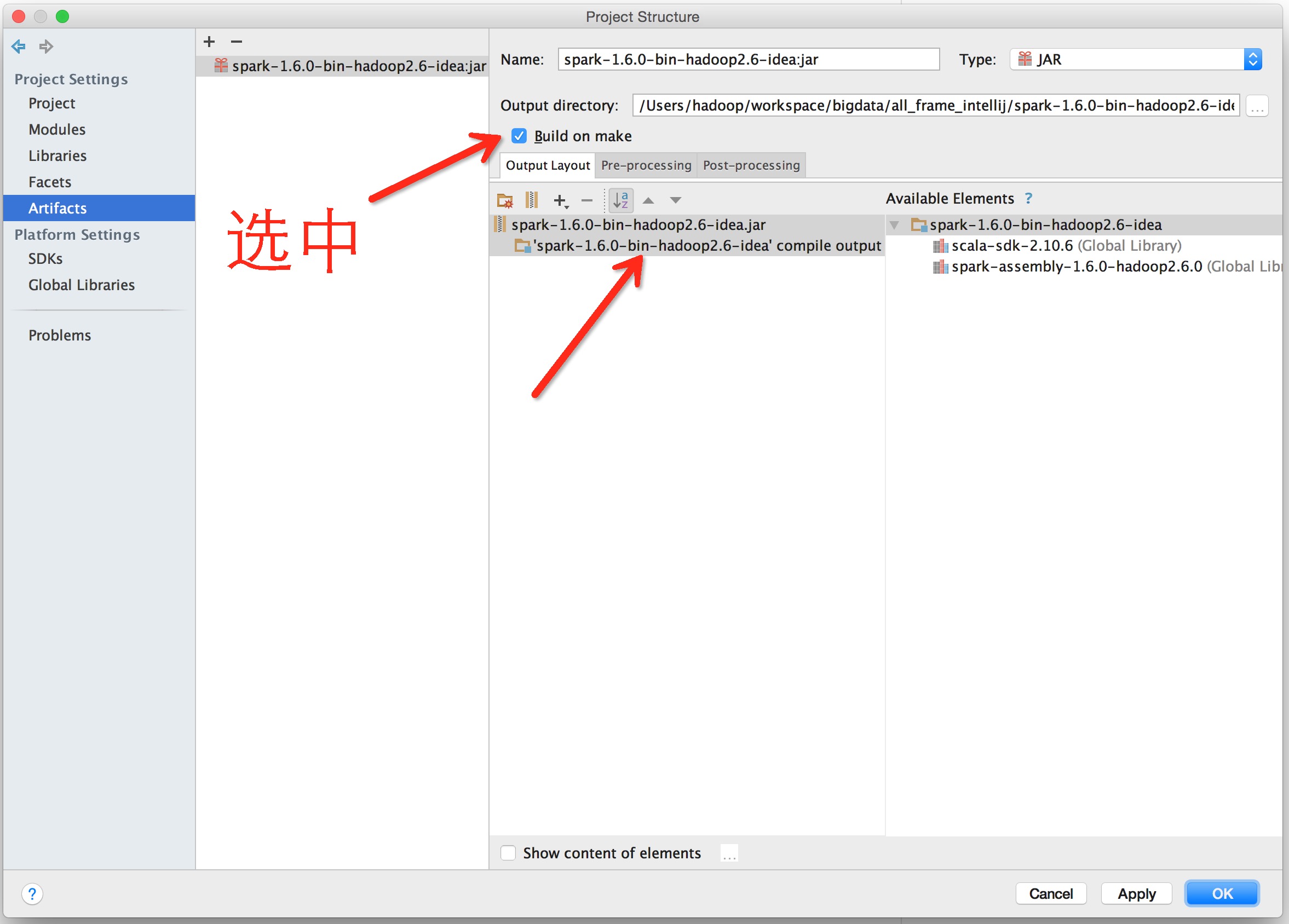
用idea工具打包,Build ==> Make Project 看工具又下方的进度,等待完成
查看jar
项目根路径/out/artifacts/spark_1_6_0_bin_hadoop2_6_idea_jar/spark-1.6.0-bin-hadoop2.6-idea.jar
查看class
项目根路径/out/production/spark-1.6.0-bin-hadoop2.6-idea/*
在项目根路径下新建submit.sh文件
#!/bin/bash SPARK_HOME=/opt/modules/bigdata/spark/spark-1.6.0-bin-hadoop2.6 $SPARK_HOME/bin/spark-submit --class com.opensourceteam.model.common.bigdata.spark.quickstart.WordCount --master spark://s0:7077 /home/hadoop/workspaces/idea/bigdata/spark/spark-1.6.0-bin-hadoop2.6-idea/out/artifacts/spark_1_6_0_bin_hadoop2_6_idea_jar/spark-1.6.0-bin-hadoop2.6-idea.jar执行 submit.sh 文件
在终端 chmod u+x /home/hadoop/workspaces/idea/bigdata/spark/spark-1.6.0-bin-hadoop2.6-idea/submit.sh sh /home/hadoop/workspaces/idea/bigdata/spark/spark-1.6.0-bin-hadoop2.6-idea/submit.sh打开界面查看运行状态